שיטה חדשה (לא יציבה עדיין) לטיפול בקטעים גדולים של זיכרון וירטואלי. מכיוון שטבלאות הזיכרון
הוירטואלי יושבות בזיכרון הנמוך - זיכרון אמיתי, הן תופסות זיכרון יקר מאד. על ידי שנוי
כמות הזיכרון שאליו מצביעים ניתן לחסוך עד 008 M זיכרון נמוך. המשמעות אינה תוספת זיכרון
לתוכניות של המשתמש, משום שהזיכרון המדובר נלקח ממרחב הזיכרון של הקרנל- הגרעין (ולא ממרחב
המשתמש), אך בהחלט מושג ייעול של פעילות המערכת.
LDSO הוא ארגון שמטרתו לקשר בין יצרני המחשבים למפתחי לינוקס. הארגון מסייע לפיתוח לינוקס
על ידי בחינת גרסאות חדשות על מגוון מכונות. בהרצאה הודגשה חשיבות צורת הפלט מריצות בוחן- כך
שניתן יהיה לנתח את התוצאות באופן ממוחשב אוטומטי, וכן הודגשה החשיבות של קבלת פלט מכל ריצת
בוחן, גם אם הריצה לא הסתיימה, נתקעה וכד'.
הכלים vocg, vocl (הרחבה של vocg על ידי PTL) מסייעים בבדיקת פרופיל התוכנית. vocg נותן סטטיסטיקה על גישה לשורות קוד.
vocl נותן דיווח עבור ריצת בוחן נתונה, אלו חלקים של הקוד כוסו. כמובן שאין
המשמעות כי כל המסלולים האפשריים כוסו- רק כי ריצן הבוחן הגיעה לשורות קוד אלו במצב מסויים.
MIA 7/9 הן חבילות המיועדות להרצה של ריצות בוחן בכמויות. 9 מריץ עבור משתמש אחד, 7 מדמה
מצב של ריבוי משתמשים. MIA נותן פלט של זמן המערכת והמשתמש בריצות הבוחן השונות.
ט'סו דן בריצות בוחן מטיפוס מיקרו (אשר בוחנות ביצועים של נקודה מסויימת בתוכנית) לעומת ריצות
מאקרו (אשר משתמשות בתרחיש סביר מהחיים, אשר מכניס לפעולה מגוון מרכיבים במערכת.
כאשר מבצעים הערכה של התוכנית באמצעות ריצות בוחן מאקרו, עלול השנוי בביצועי המרכיב הנבדק
להיטמע עקב צווארי בקבוק אחרים, ברורים יותר. חיסרון אחר של ריצות מאקרו הוא כי קשה לייצר
ריצת בוחן טובה מלאה.
ריצות מיקרו, לעומת זאת, מעודדות מיקרו-אופטימיזצייה: שפורים הניכרים רק בבצועים של ריצת
המיקרו, אך זניחים בכל הבט אחר. ריצות אלו אינן מדמות התנהגות אמיתית, ותוצאותיהן עשויות להיות
מוטות לחלוטין בגלל נקודת העבודה בה נמצאת המערכת. כמו כן, בעיות בממשקים עשויות להעלם מן
העין אם משתמשים רק בריצות מיקרו.
דייב ביצע החייאה לקוד שבמשך זמן רב לא היה לו אחראי. הקוד הסתבך עם השנים. כדי לאפשר
תחזוקתיות של הקוד, השתמש דייב בעקרונות הבאים:
כאשר קטע קוד גדול נמצא בין הוראות fedfi# (כלומר לא תמיד נכלל בקומפילציה), דייב הוציא את
קטע הקוד (באופן טיפוסי- מספר שגרות) לקובץ חיצוני, ודאג שקובץ זה יתהדר בפני עצמו. הקובץ נכלל
על ידי הוראת edulcni# במקום בו היה קודם. כך ניתן לוודא שכל הקוד עובד (או לפחות מתהדר ללא
שגיאות), כולל קוד שבדרך כלל לא נעשה בו שימוש כלל.
בוצעה חלוקה של הקוד לשגרות המבצעות פעולה אחת בלבד, כך שברור מן השם מה עושה השגרה.
כתוצאה מקרינה קוסמית, הפרות מתח, קרינת שמש וכד', עשוי להתרחש היפוך ביט בזיכרון המחשב.
כמובן שתדירות התופעה גדלה כאשר עוסקים באשכולות מחשבים גדולים.
לאיטניום יש יכולת תיקון עצמית לחלק מן השגיאות, הממומשת בחומרה (בלי לערב את מערכת
ההפעלה).
שגיאות באזורים מסוימים של הזיכרון זקוקות לשיתוף פעולה של מערכת הפעלה וחומרה. למשל,
הזיכרון של ה BLT יכול להיות מתוקן אוטומטית על ידי החומרה, אך מערכת ההפעלה צריכה לדאוג
לעדכן את ה- ehcac BLT.
אם שגיאת זיכרון ארעה בשטח זיכרון של גרעין מערכת ההפעלה, יש צורך בדרך כלל באתחול המחשב.
אם השגיאה ארעה בשטח זיכרון של המשתמש, ניתן להרוג את התהליך אשר עושה שימוש בזיכרון
הפגוע, או לטפל בבעיה בדרכים אחרות: למשל, אם דף הזיכרון הוא לקריאה בלבד, ויש לו עותק על
הדיסק הקשיח, ניתן לטעון אותו מחדש. אם הדף הוא לקריאה וכתיבה יש להרוג את כל התהליכים
שחולקים באותו דף (למשל, אם זו ספריה , לדוגמא clib, יש להרוג את כל התהליכים שמשתמשים
בשפת C).
יש בעיה בזיהוי כל התהליכים החולקים דף. על איטניום, החומרה אחראית להנפת דגל אדום כאשר
תהליך של המשתמש (ecape resu) עומד לקרוא מידע שנפגע. בצורה זו ניתן להימנע מהריגת כל
התהליכים- הרי ייתכן שהמידע שעבר שנוי לא ייקרא לעולם, ואין צורך להרוג את התהליך. במרחב
הגרעין (ecape resu) הבעיה פתוחה- ייתכן שחובה לבצע איתחול.
NUMA=Non Uniform Memory Access.
המשתמש יכול לייעל מאד את ביצועי החישוב אם יקבע ידנית (תוך
שימוש בספריה amunbil) את המיקום המועדף מבחינת מעבד וזיכרון עבור התהליך. לשם כך
המשתמש צריך להיות מודע לדברים כמו ה - kasm-UPC של המכונה הספציפית בה הוא משתמש.
מסכת UPC היא מספר אשר בו כל ביט מתאים למעבד. כך, אם המשתמש מכווין את התהליך לעבוד על
מסכת מעבדים 1100, הכוונה היא שהתהליך יכול לעבוד על מעבדים 1 או 2, אך לא על 3 ולא על 4.
המשתמש צריך להיות מודע לטופולוגיית המכונה (אילו מעבדים קשורים ישירות לאילו, מה מרחק
הקשתות בין המעבדים שאינם מחוברים ישירות) והעומס על המכונה. כמובן שתכנות כזה אינו פורטבילי.
בנוסף לכך, התחייבות יתר שנוצרת על ידי המשתמש ("משתמש שחושב שהוא חכם יותר ממערכת
ההפעלה, אך טועה") עשויה לגרום לפגיעה בביצועים.
את ביצועי ה AMUN ניתן לבחון באמצעות מערכת ריצות בוחן בשם hcnebAMUN, אותה אפשר
להריץ לבד, או מופרעת על ידי ריצות שונות (למשל על ידי hcnebkcah).
כאשר מערכת ההפעלה רוצה לבצע אופטימיזציה של הרצת תהליכים, יש כמה גורמים סותרים לעתים
שיש להביא בחשבון. איזון עומסים דוחף לכך שלא יהיו מעבדים שעומדים בטל. מצד שני, חוטים שחולקים באותו מידע בזיכרון מרוויחים כאשר הם ממוקמים על אותו מעבד (או על מעבדים
בקרובים לזיכרון הדרוש). גם כאשר מבוצע פיצול של התהליך ( fork), אם מיוצרים שני תהליכים
החולקים בהרבה מאד זיכרון קריאה-בלבד, יש רווח במיקום התהליך החדש על אותו מעבד. מצד שני, אם
תהליך אחד יוצר חוטים רבים או מתפצל פעמים רבות, העומס על המעבד הסמוך לזיכרון יהיה גדול מדי,
ועדיף להצמיד את התהליכים החדשים למעבדים אחרים.
כרגע אין איזון עומסים התחלתי (כלומר ברגע תחילת הריצה של החוט או התהליך) עבור enolc , krof (יצירת תהליך חדש החולק עותק של הזיכרון)
וחוטים של PMnepo. חוטים מבוצעים אוטומטית על המעבד שהריץ את התהליך לו הם שייכים.
במהלך פעולת התהליכים, נדגם אורך התור הממתין למעבד (מדי 004 מילישניה על מעבד עמוס, מדי 5
מילישניה על מעבד פנוי), ומבוצע איזון עומסים: מעבדים פנויים יותר מקבלים חלק מן התור הממתין
למעבדים עמוסים. כך מבוצעת הגירת תהליכים.
בשלב זה אי אפשר להגר את הזיכרון הדרוש לתהליכים.
כאשר עומדים להקצות זיכרון חדש, נשאלת השאלה היכן יש להקצותו. האם על המעבד הנוכחי שמריץ
את התהליך? או אולי על המעבד בו הורץ התהליך ברוב הפעמים בהן קיבל זמן חישוב? או על המעבד
אליו סמוכים רוב דפי הזיכרון שהתהליך השתמש בהם עד כה? בחירה לא נכונה תוביל לפיזור של
הזיכרון: חלקים מהזיכרון של התהליך יישבו בסמוך לכמה מעבדים, ולא יהיה מעבד מיטבי עבור תהליך
זה: לא יהיה אף מעבד הסמוך לכל הזיכרון.
מחקר עתידי יעסוק בשאלות הבאות:
- מתי יש לבצע מעבר תהליכים בין צמתים (יקר יותר)?
- דחיפה אקטיבית של תהליכים חזרה לצומת האם שלהם.
- מודעות להיררכיה רבת רמות של צמתים (מרחק בין צמתים).
- גניבה של קבוצת תהליכים בו זמנית מצומת לצומת.
- מיון המועמדים לגניבה בין צמתים.
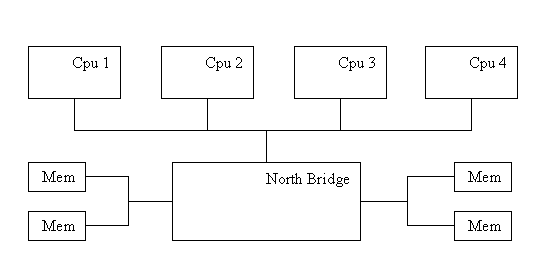
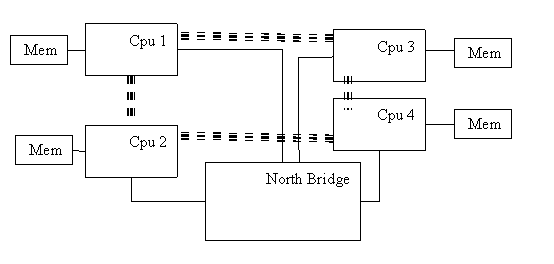
ה - xitlA של IGS מכיל כיום 46 מעבדי איטניום 2, המקושרים ביניהם ב IPM מעל זיכרון משותף.מצ"ב
רשימת ריצות בוחן מסוגים שונים, שבוצעו לאלטיקס לעומת מספר מחשבים אחרים.
בחינת ביצועים שנעשתה למערכות הקבצים 2txe, kcabetirw.3txe, sfrezier, SFX העלתה כי 2txe ו-
SFX מתמודדות הרבה יותר טוב עם מערכות גדולות, כאשר ל SFX יש אפילו ביצועים טובים במעט
משל 2txe.
IGS מצאה את גרסת לינוקס 20.4.2 כגרסה המועדפת ל-AMUN, פרט לכך שהיא מבצעת יותר מדי
הגירה של תהליכים.
רסטי מנה רשימת כלים שכדאי לדעתו לכל מפתח להכיר:
ספרים מומלצים :
רסטי מנה דרכים לווידוא של שימוש נכון בשגרות (בסדר יורד של עוצמה), כך שאפילו משתמשים
שאינם מכירים את הקוד שמאחורי שמות הפונקציות לא יתקשו להשתמש בהן נכון:
- 1. בלתי אפשר ללנקג' קוד לא נכון- למשל, אם יש חלק בקוד שלא אמורים להגיע אליו בשום
מקרה, והמהדר אמור להשמיטו החוצה, לקרוא בו לפונקציה שאינה קיימת
בעליל, כך שלא ניתן להשלים את ההידור אם קטע הקוד לא הושמט.
- 2. הודעת שגיאה של המהדר אם יש שימוש לא נכון- למשל על ידי קביעת טיפוסים מיוחדים לקלט
הפונקציה, במקום להשתמש בטיפוסים רגילים כמו tni.
- 3. אופן השימוש הפשוט ביותר הוא הנכון.
- 4. שמה של הפונקציה מגלה בדיוק מה היא עושה- למשל, שגרה ששמה מתחיל ב- _yrt לא תטעה
אף אחד לחשוב שהיא תמיד מצליחה.
- 5. יציאה בהודעת שגיאה בזמן הריצה אם יש שימוש לא נכון.
- 6. שימוש במוסכמות מקובלות יוביל לשימוש נכון.
- 7. מעקב אחר התיעוד יוביל לשימוש נכון.
- 8. קריאת הקוד תוביל לשימוש נכון.
- 9. קריאת המכתב המתאים שנשלח מתישהו תוביל לשימוש נכון.
כמו כן, רסטי מנה כמה דרכים פרטניות יותר להימנע מתקלות מנשקים:
- 1. למנוע גישה למודול בכמה רמות: לאחד את המנשק לרמה אחת. לחליפין, להבהיר שהמנשק
ברמה הנמוכה יותר מיועד לשימוש בהזדמנויות מיוחדות בלבד.
- 2. העדר מנשק מסודר עדיף על מנשק גרוע.
- 3. אל תירתע משכפול קוד, אם הוא מפשט את המנשק.
- 4. קח מנשקים מהמשתמשים.
- 5. אל תעשה את המנשקים קלים מדי לשימוש: עשה אותם בטוחים לשימוש.
- 6. כתיבת תיעוד למנשקים עוזרת לעיצובם:
- a. חשוב מנקודת המבט של המשתמש.
- b. אם אתה לא יכול להסביר איך או מדוע זה עובד, המנשק שלך גרוע.
- c. צריכה להיות לך סימפטיה רבה לקוראים: יום אחד, זה עלול להיות אתה.
תכונותיו החשובות של מתכנת על פי לארי וול הן עצלות, חוסר סבלנות והיבריס. רסטי מוסיף לכך את
הפחד מסיבוך.
כמו כן, רסטי מציין כי קוד שלא נבדק הוא קוד שבור.
 Elements of Programming Style , Kernigham and Plauger
Elements of Programming Style , Kernigham and Plauger  "The Lions book"
"The Lions book"